Les années 1960 ont constitué un tournant pour les système d'exploitation. Dans le cadre du projet MAC au MIT (Massachusset Institute of Technology), le système d'exploitation CTTS est publié en 1961. C'est l'un des tout premiers système d'exploitation à temps partagé, permettant à plusieurs utilisateurs d'utiliser un ordinateur en même temps. C'est une déclinaison du multitâche apparu peu de temps avant, et c'est cette apparente simultaneité dans l'exécution des programmes qui a permis de se diriger vers l'informatique moderne.
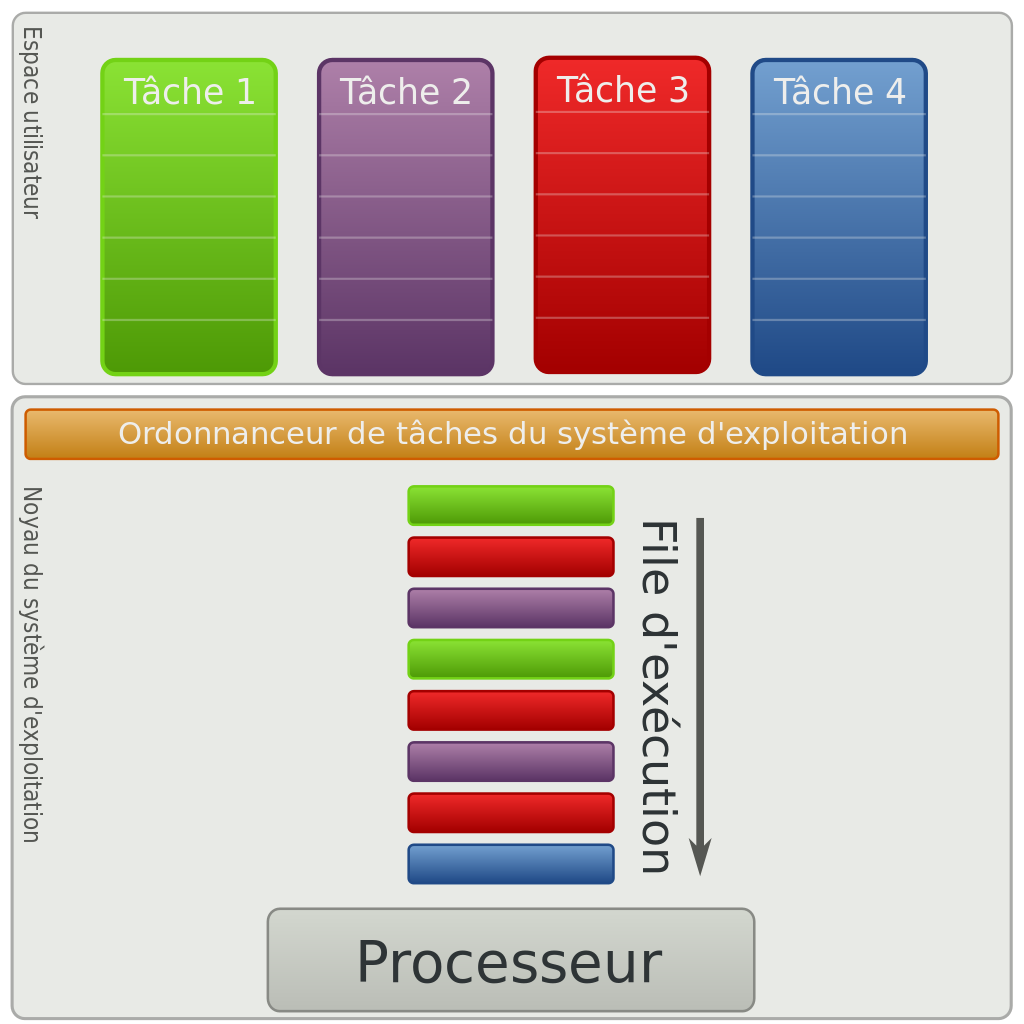
Dans les années 1970 les ordinateurs personnels n'étaient pas capables d'exécuter plusieurs tâches à la fois : on lancait un programme et on y restait jusqu'à ce que celui-ci plante ou se termine. Les systèmes d'exploitation récents (Windows, Linux ou osX par exemple) permettent d'exécuter plusieurs tâches simultanément - ou en tous cas, donner l'impression que celles-ci s'exécutent en même temps. A un instant donné, il n'y a donc pas un mais plusieurs programmes qui sont en cours d'exécution sur un ordinateur : on les nomme processus. Une des tâches du système d'exploitation est d'allouer à chacun des processus les ressources dont il a besoin en termes de mémoire, entrées-sorties ou temps processeur, et de s'assurer que les processus ne se gênent pas les uns les autres.
si l'on prend l'exemple du smartphone, cet ordinateur que l'on a dans la poche, alors que nous regardons une vidéo, il va suivre les antennes relais et se synchroniser avec, écouter s'il y a un appel téléphonique ou des SMS qui arrive, vérifier les nouveaux courriers électroniques, mettre à jour les notifications des différents réseaux sociaux,etc. Il y a toute une myriade de processus qui s'éxécute de façon «simultanée».
Nous avons tous été confrontés à la problématique de la gestion des processus dans un système d'exploitation, en tant qu'utilisateur :
Nous allons voir en détails dans cette séquence comment les processus sont gérés dans le système d'exploitation Linux.
Il ne faut donc pas confondre le fichier contenant un programme (portent souvent l'extension .exe sous windows) et le ou les processus qu'il engendre quand il est exécuté : Un programme est juste un fichier contenant une suite d'instructions (firefox.exe par exemple) alors que les processus sont des instances de ce programme ainsi que les ressources nécessaires à leur exécution (plusieurs fenêtres de firefox ouvertes en même temps).
Pour prendre une image assez classique, si une recette de cuisine correspond au code source du programme, les tâches du cuisinier en train de préparer cette recette dans sa cuisine correspondent aux processus.
La création d'un processus peut intervenir
Un processus peut créer un ou plusieurs processus à l'aide d'une commande système ("fork" sous les systèmes de type Unix). Imaginons un processus A qui crée un processus B. On dira que A est le père de B et que B est le fils de A. B peut, à son tour créer un processus C (B sera le père de C et C le fils de B). On peut modéliser ces relations père/fils par une structure arborescente.
Si un processus est créé à partir d'un autre processus, comment est créé le tout premier processus ?
Sous un système d'exploitation comme Linux, au moment du démarrage de l'ordinateur un tout premier processus (appelé processus 0 ou encore Swapper
est créé à partir de "rien" (il n'est le fils d'aucun processus). Ensuite, ce processus 0 crée un processus souvent appelé "init" ("init" est donc le fils du processus 0).
À partir de "init", les processus nécessaires au bon fonctionnement du système sont créés (par exemple les processus "crond", "inetd", "getty",...)
Puis d'autres processus sont créés à partir des fils de "init"...
Ouvrir le Simulateur terminal linux aussi apellé shell >
Dans un terminal, tester l'instruction pstree -p qui permet de visualiser l'arbre de processus. Recopier ci-dessous, l'arbre des processus :
Il est possible de visualiser les processus grâce à la commande ps -eF.
Pour un affichage page par page, utilisez ps -eF | more
Un processus est caractérisé par un identifiant unique : son PID (Process Identifier).
Lorsqu'un processus engendre un fils, l'OS génère un nouveau numéro de processus pour le fils. Le fils connaît aussi le numéro de son père :
le PPID (Parent Process Identifier).
python Une commande indispensable à connaître sous Linux pour inspecter les processus est la commande top.
L'affichage se rafraîchit en temps réel contrairement à ps qui fait un instantané.
Voici quelques option qui s'activent s'activent par des raccourcis clavier. En voici quelques uns :
toptop.Pour tuer un processus, on lui envoie un signal de terminaison. On en utilise principalement deux :
Pour terminer proprement un processus :
vous lui enverrez donc un signal SIGTERM en tapant : la commande shell kill -15 PID où PID désigne le numéro du processus à quitter proprement.
Si ce dernier est planté et ne réagit pas à ce signal, alors vous pouvez vous en débarasser en tapant kill -9 PID.
killTous les systèmes d'exploitation "modernes" (Linux, Windows, macOS, Android, iOS...) sont capables de gérer l'exécution de plusieurs processus en même temps. Mais pour être précis, cela n'est pas en véritable "en même temps", mais plutôt un "chacun son tour".
Un système d’exploitation multitâche ré-attribue périodiquement à l’UC une tâche différente dans le but de faire progresser l’exécution de plusieurs programmes à la fois.
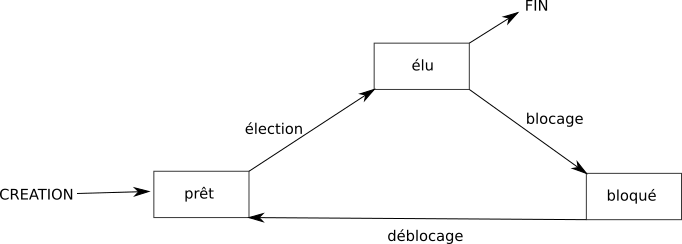
Voici les différents états :
Le passage de l'état "prêt" vers l'état "élu" constitue l'opération "d'élection".
Le passage de l'état élu vers l'état bloqué est l'opération de "blocage".
Pour se terminer, un processus doit obligatoirement se trouver dans l'état "élu".
On peut résumer tout cela avec le diagramme suivant :
Il est vraiment important de bien comprendre que le "chef d'orchestre" qui attribue aux processus leur état "élu", "bloqué" ou "prêt" est
le système d'exploitation .
On dit que le système gère l'ordonnancement des processus (tel processus sera prioritaire sur tel autre...)
Chose aussi à ne pas perdre de vu : Pour libérer une ressource, un processus doit obligatoirement être dans un état "élu".
Afin d'élire quel processus va repasser en mode "éluu", l'ordonnanceur applique un algorithme prédéfini lors de la conception de l'OS.
Le choix de cet algorithme va impacter directement la réactivité du système et les usages qui pourront en être fait.
C'est un élément critique du système d'exploitation.
Sous Linux, on peut passer des consignes à l'ordonnanceur en fixant des priorités aux processus dont on est propriétaire :
Cette priorité est un nombre NI entre -20 (plus prioritaire) et +20 (moins prioritaire).
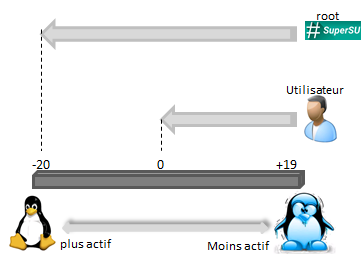
Pour gérer l'élection d'un processus,on peut agir à 2 niveaux :
nicereniceles colonne PR et NI de la commande top montrent le niveau de priorité de chaque processus
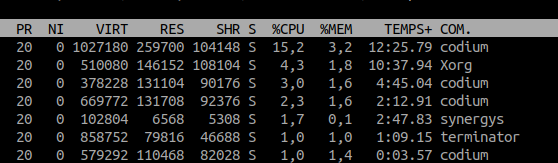
Le lien entre PR et NI est simple : PR = NI + 20 ce qui fait qu'une priorité PR de 0 équivaut à un niveau de priorité maximal.
Exemple : Pour baisser la priorité du process terminator dont le PID est 21523, il suffit de taper : renice +10 21523
Nous avons vu comment une hiérarchie de processus se crée au fur et à mesure de l'utilisation de l'ordinateur, tous ayant pour racine le processus initial (systemd ou init sur les distributions linux).
Commençons par un programme simple :
#!/usr/bin/python3
def f1():
for _ in range(5):
print("Bonjour !")
print("Comment vas-tu aujourd'hui ?")
sleep(0.01)
def f2():
for _ in range(5):
print("Ça va ?")
print()
sleep(0.01)
f1()
f2()
1. Recopiez le code ci dessus dans un fichier que vous nommerez sequentiel.py et exécutez le.
2. Chronométrer le temps mis pour executer 100 fois le programme ci-dessus.
Lorsque vous exécutez le programme, vous avez la fonction f1 qui s'éxécute complétement, puis
ensuite la fonction f2 qui s'éxécute.
L'excecution des fonctions est dite séquentielle .
Un thread est un processus qui va partager avec notre programme l'espace des données et va s'éxécuter de façon simultané avec d'autres thread. On parle de processus léger. Ils peuvent être très utile, mais peuvent aussi causer de multiples problèmes. Mettons les choses en pratique. Pour cela, nous allons utiliser la bibliothèque threading avec le code ci dessous :
#!/usr/bin/python3
from threading import Thread
from time import sleep
def f1():
for _ in range(5):
print("Bonjour !")
print("Comment vas-tu aujourd'hui ?")
sleep(0.01)
def f2():
for _ in range(5):
print("Très bien")
print("Merci et bonne journée.")
sleep(0.01)
p1 = Thread(target=f1)
p2 = Thread(target=f2)
p1.start()
p2.start()
p1.join()
p2.join()
1. Recopiez le code ci dessus dans un fichier que vous nommerez concurrente.py et exécutez le,
plusieurs fois de préférence. Que remarquez vous ?
2. Chronométrer le temps mis pour executer 100 fois le programme ci-dessus.
3. Comparer avec la méthode séquentielle.
from threading import Thread
from time import sleep
Les deux premières lignes du programme se contentent d'importer la classe Thread du module
threading et la fonction sleep du module time (nous avons besoin de ralentir le processus avec
sleep sinon la première fonction s'éxécuterait trop vite et afficherait tout d'un coup).
Les fonctions f1 et f2
sont exactement les même que dans la version séquentielle. Mais c'est dans la partie principale du programme
que tout change.
p1 = Thread(target=f1)
p2 = Thread(target=f2)
p1.start()
p2.start()
p1.join()
p2.join()
Ici, nous n'éxécutons pas directement les fonctions f1 et f2. Nous créons deux objets
de la classe Thread. Ce sont des processus légers qui vont partager l'espace mémoire de notre
programme principal et s'éxécuter de façon parallèle. Les deux lignes suivantes appellent la méthode
start sur
les Thread, et va lancer leur exécution. Mais pendant que le premier s'éxécute, le programme continue et va
lancer le second.
Enfin, nous utilisons la méthode join sur ces deux threads. En effet, le programme principal
continue de s'exécuter pendant que les threads tournent, et si il se termine, il met fin à tous ses threads. La
méthode join force le programme principal à attendre la fin des threads.
L'avantage principal, c'est de pouvoir faire plusieurs choses en même temps. Surtout si on travaille sur une machine qui a plusieurs processeur. Par exemple, on peut avoir une machine qui a deux processeurs, chaque processeur ayant quatre cœurs, chaque cœeurs pouvant lui même exécuter deux threads. on va pouvoir au total exécuter en parallèle 16 threads !
Imaginons que j'ai un programme qui doit bêtement faire 400 calculs. On va simuler cela par un petit
sleep
avec le code suivant
#!/usr/bin/python3
from time import sleep
# Variable globale
compteur = 0
limite = 400
def calcul():
global compteur
for c in range(limite):
temp = compteur
# simule un traitement nécessitant des calculs
sleep(0.000000001)
compteur = temp + 1
compteur = 0
calcul()
print(compteur)
1. Recopiez le code ci dessus dans un fichier que vous nommerez calcul.py et exécutez le. Vérifiez
qu'il affiche bien 400.
Je sais que je suis sur une machine qui peut exécuter 8 threads de façon parallèle et je me dis qu'il serait plus rapide de faire 4 thread différents qui font chacun un quart des calculs. En faisant ça, le résultat devrait être donné environ 4 fois plus vite. Traduisons cela avec du code :
#!/usr/bin/python3
from threading import Thread
from time import sleep
# Variable globale
compteur = 0
limite = 100
def calcul():
global compteur
for c in range(limite):
temp = compteur
# simule un traitement nécessitant des calculs
sleep(0.000000001)
compteur = temp + 1
compteur = 0
mesThreads = []
for i in range(4): # Lance en parallèle 4 exécutions de calcul
p = Thread(target = calcul)
p.start() # Lance calcul dans un processus léger à part.
mesThreads.append(p)
# On attend la fin de l'exécution des threads.
for p in mesThreads :
p.join()
print(compteur)
Recopiez le code ci dessus dans un fichier que vous nommerez calcul-concurrent.py et exécutez
le, de
préférence plusieurs fois.
Ah. Le résultat n'est pas du tout le résultat attendu. Chaque thread se lance et fait 100 calcul, mais mon compteur à la fin ne vaut en général même pas 100 ! Ce résultat est très perturbant quand on le rencontre pour la première fois, et cela explique la réticence de bien des développeurs à l'égard des threads. On peut lire sur bien des forums de développeur «Threads are EVIL, don't use them !». Mais non, il ne sont pas le diable, il faut juste être parfaitement conscient de ce qui se passe. Ils sont même indispensable dans bien des programmes, particulièrment tous les programmes client/serveur qui doivent répondre à un grand nombre de requêtes concurrentes.
Il n'y a rien d'illogique ou d'aléatoire dans le fonctionnement de notre programme. Il faut simplement habituer notre esprit à l'exécution en parallèle :
au final, compteur a été incrémenté 4 fois mais de fait de l'exécution en parallèle compteur ne vaut pas 14 mais 12 ! cela explique que notre compteur au final ne vaut pas 400 car sa sauvegarde dans des variables temporaires fait que la plupart des incrémentations ne sont pas prises en compte.
Le résultat est aléatoire par ce que les threads s'exécutent dans un ordre qui peut varier, comme nous l'avons vu sur l'exemple des salutations. C'est le principal problème avec les threads : on ne maîtrise absolument pas l'ordre dans lequel ils sont exécutés, et il faut en tenir compte dès la conception.
Vous vous en doutez, la réponse est oui. Comment ? Il existe un mécanisme qui va nous ralentir potentiellement
un peu mais qui évite ce genre de problèmes : les verrous. Ce sont des objets de la classe
Lock du module threading. Dans notre cas, ils ont deux méthodes qui nous intéressent.
acquire s'accapare le verrou s'il est disponible, sinon elle attend qu'il se libère.
release libère le verrou.
Ce verrou sera une variable globale du programme principal qui sera partagé entre les threads. Notre programme devient alors le suivant :
#!/usr/bin/python3
from threading import Thread,Lock
from time import sleep
# Variable globale
compteur = 0
limite = 100
verrou = Lock()
def calcul():
global compteur
for c in range(limite):
# Début de la section critique
verrou.acquire()
temp = compteur
# simule un traitement nécessitant des calculs
sleep(0.000000001)
compteur = temp + 1
# fin de la section critique
verrou.release()
compteur = 0
mesThreads = []
for i in range(4): # Lance en parallèle 4 exécutions de calcul
p = Thread(target = calcul)
p.start() # Lance calcul dans un processus léger à part.
mesThreads.append(p)
# On attend la fin de l'exécution des threads.
for p in mesThreads :
p.join()
print(compteur)verrou.py et exécutez
le. Vérifiez que cette fois le résultat est bien 400.Alors ? Nos problèmes sont résolus ? En fait, non, ils ne font que commencer comme on va le voir dans la partie suivante sur l'interblocage.
| A | B |
| demande R | demande S |
| libère R | libère S |
| demande S | demande R |
| libère S | libère R |
| A | B |
| demande R | demande S |
| libère R | demande R |
| demande S | libère R |
| libère S | libère S |
| A | B |
| demande R | demande S |
| demande S | libère S |