Dans les années 1970 les ordinateurs personnels n'étaient pas capables d'exécuter plusieurs tâches à la fois : on lancait un programme et on y restait jusqu'à ce que celui-ci plante ou se termine. Les systèmes d'exploitation récents (Windows, Linux ou osX par exemple) permettent d'exécuter plusieurs tâches simultanément - ou en tous cas, donner l'impression que celles-ci s'exécutent en même temps. A un instant donné, il n'y a donc pas un mais plusieurs programmes qui sont en cours d'exécution sur un ordinateur : on les nomme processus. Une des tâches du système d'exploitation est d'allouer à chacun des processus les ressources dont il a besoin en termes de mémoire, entrées-sorties ou temps processeur, et de s'assurer que les processus ne se gênent pas les uns les autres.
Nous avons tous été confrontés à la problématique de la gestion des processus dans un système d'exploitation, en tant qu'utilisateur :
Nous allons voir en détails dans cette séquence comment les processus sont gérés dans le système d'exploitation Linux.
Il ne faut donc pas confondre le fichier contenant un programme (portent souvent l'extension .exe sous windows) et le ou les processus qu'il engendre quand il est exécuté : Un programme est juste un fichier contenant une suite d'instructions (firefox.exe par exemple) alors que les processus sont des instances de ce programme ainsi que les ressources nécessaires à leur exécution (plusieurs fenêtres de firefox ouvertes en même temps).
Pour prendre une image assez classique, si une recette de cuisine correspond au code source du programme, le cuisinier en train de préparer cette recette dans sa cuisine correspond à un processus.
La création d'un processus peut intervenir
Un processus peut créer un ou plusieurs processus à l'aide d'une commande système ("fork" sous les systèmes de type Unix). Imaginons un processus A qui crée un processus B. On dira que A est le père de B et que B est le fils de A. B peut, à son tour créer un processus C (B sera le père de C et C le fils de B). On peut modéliser ces relations père/fils par une structure arborescente.
Si un processus est créé à partir d'un autre processus, comment est créé le tout premier processus ?
Sous un système d'exploitation comme Linux, au moment du démarrage de l'ordinateur un tout premier processus (appelé processus 0 ou encore Swapper
est créé à partir de "rien" (il n'est le fils d'aucun processus). Ensuite, ce processus 0 crée un processus souvent appelé "init" ("init" est donc le fils du processus 0).
À partir de "init", les processus nécessaires au bon fonctionnement du système sont créés (par exemple les processus "crond", "inetd", "getty",...)
Puis d'autres processus sont créés à partir des fils de "init"...
Dans un terminal, tester l'instruction pstree qui permet de visualiser l'arbre de processus.
Il est possible de visualiser les processus grâce à la commande ps -eF.
Pour un affichage page par page, utilisez ps -eF | more
Un processus est caractérisé par un identifiant unique : son PID (Process Identifier).
Lorsqu'un processus engendre un fils, l'OS génère un nouveau numéro de processus pour le fils. Le fils connaît aussi le numéro de son père :
le PPID (Parent Process Identifier).
Une commande indispensable à connaître sous Linux pour inspecter les processus est la commande top.
L'affichage se rafraîchit en temps réel contrairement à ps qui fait un instantané.
Voici quelques option qui s'activent s'activent par des raccourcis clavier. En voici quelques uns :
top top .Pour tuer un processus, on lui envoie un signal de terminaison. On en utilise principalement deux :
Pour terminer top proprement, vous lui enverrez donc un signal SIGTERM en tapant le numéro 15. Cela est équivalent à la commande shell kill -15 PID où PID désigne le numéro du processus à quitter proprement.
Si ce dernier est planté et ne réagit pas à ce signal, alors vous pouvez vous en débarasser en tapant kill -9 PID.
ps ou topkill
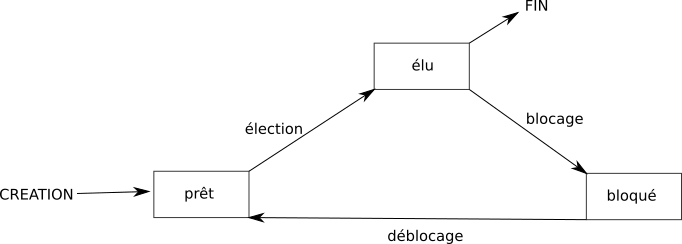
Voici les différents états :
Le passage de l'état "prêt" vers l'état "élu" constitue l'opération "d'élection".
Le passage de l'état élu vers l'état bloqué est l'opération de "blocage".
Pour se terminer, un processus doit obligatoirement se trouver dans l'état "élu".
On peut résumer tout cela avec le diagramme suivant :
Il est vraiment important de bien comprendre que le "chef d'orchestre" qui attribue aux processus leur état "élu", "bloqué" ou "prêt" est
le système d'exploitation .
On dit que le système gère l'ordonnancement des processus (tel processus sera prioritaire sur tel autre...)
Chose aussi à ne pas perdre de vu : Pour libérer une ressource, un processus doit obligatoirement être dans un état "élu".
Afin d'élire quel processus va repasser en mode "éluu", l'ordonnanceur applique un algorithme prédéfini lors de la conception de l'OS.
Le choix de cet algorithme va impacter directement la réactivité du système et les usages qui pourront en être fait.
C'est un élément critique du système d'exploitation.
Sous Linux, on peut passer des consignes à l'ordonnanceur en fixant des priorités aux processus dont on est propriétaire :
Cette priorité est un nombre entre -20 (plus prioritaire) et +20 (moins prioritaire).
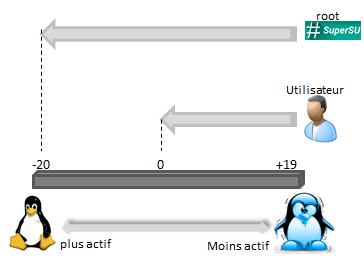
Pour gérer l'élection d'un processus,on peut agir à 2 niveaux :
nicereniceles colonne PR et NI de la commande top montrent le niveau de priorité de chaque processus
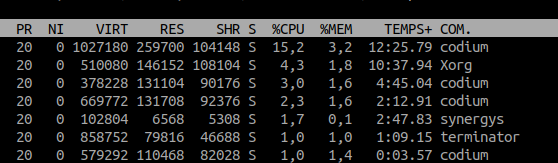
Le lien entre PR et NI est simple : PR = NI + 20 ce qui fait qu'une priorité PR de 0 équivaut à un niveau de priorité maximal.
Exemple : Pour baisser la priorité du process terminator dont le PID est 21523, il suffit de taper : renice +10
Nous allons tester l'efficacité du paramètre renice de l'ordonnanceur sur le temps d'exécution d'un programme python.
def bidon(): a = 0 for i in range(100000): a += a**3
cd et taper la commande python3 (Vous venez d'ouvrir un interpréteur python)
>>> from timeit import timeit >>> import test >>> timeit(test.bidon, number = 100)
timeit(test.bidon, number = 100) et expliquer la moins bonne performance.python3.python3) en mettant un renice à +10.timeit(test.bidon, number = 100) dans le shell python.Soit deux processus P1 et P2, soit deux ressources R1 et R2. Initialement, les deux ressources sont "libres" (utilisées par aucun processus). Le processus P1 commence son exécution (état élu), il demande la ressource R1. Il obtient satisfaction puisque R1 est libre, P1 est donc dans l'état "prêt". Pendant ce temps, le système a passé P2 à l'état élu : P2 commence son exécution et demande la ressource R2. Il obtient immédiatement R2 puisque cette ressource était libre. P2 repasse immédiatement à l'état élu et poursuit son exécution (P1 lui est toujours dans l'état prêt). P2 demande la ressource R1, il se retrouve dans un état bloqué puisque la ressource R1 a été attribuée à P1 : P1 est dans l'état prêt, il n'a pas eu l'occasion de libérer la ressource R1 puisqu'il n'a pas eu l'occasion d'utiliser R1 (pour utiliser R1, P1 doit être dans l'état élu). P2 étant bloqué (en attente de R1), le système passe P1 dans l'état élu et avant de libérer R1, il demande à utiliser R2. Problème : R2 n'a pas encore été libéré par P2, R2 n'est donc pas disponible, P1 se retrouve bloqué.
Résumons la situation à cet instant : P1 possède la ressource R1 et se trouve dans l'état bloqué (attente de R2), P2 possède la ressource R2 et se trouve dans l'état bloqué (attente de R1)
Cette situation est qualifiée 'interblocage (deadlock en anglais).
Les interblocages sont des situations de la vie quotidienne. Un exemple est celui du carrefour avec priorité à droite où chaque véhicule est bloqué car il doit laisser le passage au véhicule à sa droite.
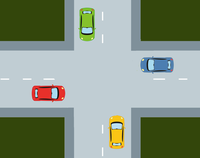
Imaginez des situations de la vie quotidienne - comme l'exemple du carrefour - où un interblocage peut survenir.